Medallion Lakehouse Architecture with Azure databricks, datafactory and DBT
This blog outlines important components and steps involved in building a medallion lakehouse architecture on Microsoft Azure.
Components of Medallion lakehouse architecture
I will introduce and demonstrate how these tools work together with Databricks Medallion architecture.
Azure databricks (ADB):
Databricks is popular service/tool to build data Lakehouse architecture. Databricks is built on top of popular opensource Apache Spark technology for big data processing. It is a complex process to build and manage a cluster with Apache Spark. This is where Databricks came into picture and made the entire process of creating and managing the cluster easy. Databricks on Azure utilizes the infrastructure capabilities of cloud and makes it intuitive to use. Azure powers the computation and storage layers, integrates with data and orchestration tools, provides security and monitoring capabilities.
Azure Data factory (ADF):
Datafactory is a integration and orchestration tool on Azure cloud. It can also host traditional microsoft specific on-prem ETL tool called SSIS. It connects to various data providers and pull data into azure datalake storage before processing. It facilitates other azure tools like azure databricks, azure functions and azure LogicApps to do specific data integration and processing.
Data Build Tool (DBT):
DBT is a transformation tool in the ETL/ELT process. There is a lot of buzz around DBT in data community. It is an open source command line tool written in Python. DBT focusses on the transformation, so it doesn’t extract or load data, but only transforms data. It is declarative and supports git review process, unit testing, monitoring, data lineage and easy documentation.
Azure data lake storage (ADLS gen2):
It is a data storage services for big data. 3 things differentiates ADLS gen2 from regular azure storage.
- It can store very large data (in peta bytes).
- Gives hierarchical data folder structure and granular security at each folder and files level.
- Integrates with Azure AD (Entra) to provide ACL and RBAC.
AzureSQL
Deploy with default AdventureWorks database.
Azure KeyVault.
Required to store ADLS2 token which is used by databricks to connect to datalake.
Make sure you create above resources in your azure resource groups.
Usecase
For building the use case, we’ll be using an Azure SQL database that is configured with sample data: AdventureWorks. This database will play the role as source from which we’ll be getting the data. The end goal is to build a simple and user-friendly data model that is ready for consumption.
Architecture
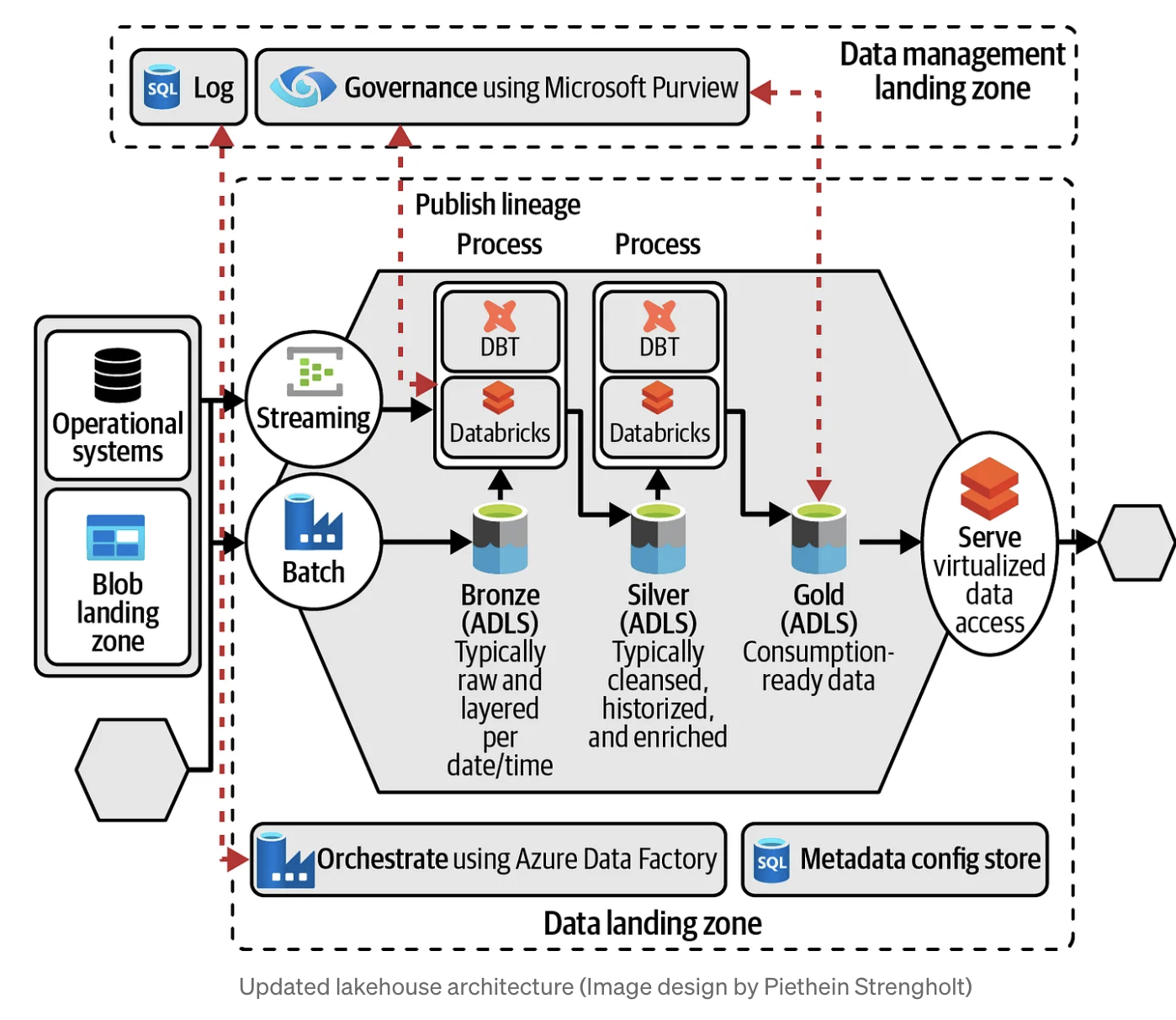
Alternative approaches on Azure
We could use other azure services instead of Databricks
1
2
1. Azure Synapse Analytics: It combines the traditional microsoft data warehouse with modern azure data services.
2. Microsoft Fabric: As of August 2023, It is still in preview and there is lot of hype around this offering. It is unified all-in-one analytics solution for all your data needs; Data lake (OneLake) + Data engineering + data integration + Data warehousing + Data Science + Real time analytics. On high level, to me, it combines the power of Databricks (lakehouse + machine learning) and Snowflage (cloud data warehouse).
Configurations
Create 3 containers in ADLS2 account: bronze, silver and gold
The bronze container will be used for capturing all raw ingested data. We’ll use Parquet files, because no versioning is required. We will use an YYYYMMDD partition scheme for adding newly loaded data to this container.
The silver container will be used for slightly transformed and standardized data. The file format for silver is Delta. For the design, we’ll develop slowly changing dimensions using DBT.
At last, there’s gold, which will be used for the final integrated data. Again, we’ll use DBT to join different datasets together. The file format for gold is Delta as well.
Create ADF pipeline
Here we weill pull data from AdventureWorks on AzureSQL. Query used
1
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'BASE TABLE' AND TABLE_SCHEMA = 'SalesLT'
Follow this video: https://www.youtube.com/watch?v=KsO2FHQdILs. For the entire flow, three datasets are needed: TableList, SQLTable, ParquetTable.
Final state of the ADF configurations are available in this git repo: https://github.com/rameshagowda/azuredatafactory
ADF final state screenshots that shows parameters, linkedservices and calling databricks notebooks from ADF
Note that ADF calls databricks notebooks that will do data transformation using DBT.
Configure Databricks and KeyVault
Open Azure databricks workspace On Azure portal, you either create a serviceprincipal or managed identity so that Databricks can access Keyvault then copy the ADLS2 account token and store it in KeyVault as Secret. After creating your secret, ensure that your DataBricks service principle has list and read rights on your secrets. You can configure this under Access Policies. To validate that everything works as expected, Create a new DataBricks Notebook and type in the following information:
1
2
abcd = dbutils.secrets.get('dbtScope','blobAccountKey')
print(abcd)
Next, add the mounting points to your storage containers. Create another notebook and execute the following code for adding mounting points to bronze, silver and gold:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
#mount bronze
dbutils.fs.mount(
source='wasbs://bronze@<<storageaccount>>.blob.core.windows.net/',
mount_point = '/mnt/bronze',
extra_configs = {'fs.azure.account.key.<<storageaccount>>.blob.core.windows.net': dbutils.secrets.get('dbtScope','blobAccountKey')}
)
#mount silver
dbutils.fs.mount(
source='wasbs://silver@<<storageaccount>>.blob.core.windows.net/',
mount_point = '/mnt/silver',
extra_configs = {'fs.azure.account.key.<<storageaccount>>.blob.core.windows.net': dbutils.secrets.get('dbtScope','blobAccountKey')}
)
#mount gold
dbutils.fs.mount(
source='wasbs://gold@<<storageaccount>>.blob.core.windows.net/',
mount_point = '/mnt/gold',
extra_configs = {'fs.azure.account.key.<<storageaccount>>.blob.core.windows.net': dbutils.secrets.get('dbtScope','blobAccountKey')}
)
dbutils.fs.ls("/mnt/bronze")
dbutils.fs.ls("/mnt/silver")
dbutils.fs.ls("/mnt/gold")
then, create a databricks notebook with dynamic script which accepts parameters from ADF.
#fetch parameters from Azure Data Factory
table_schema=dbutils.widgets.get("table_schema")
table_name=dbutils.widgets.get("table_name")
filePath=dbutils.widgets.get("filePath")
#create database
spark.sql(f'create database if not exists {table_schema}')
#create new external table using latest datetime location
ddl_query = """CREATE OR REPLACE TABLE """+table_schema+"""."""+table_name+"""
USING PARQUET
LOCATION '/mnt/bronze/"""+filePath+"""/"""+table_schema+"""."""+table_name+""".parquet'
"""
#execute query
spark.sql(ddl_query)
I used below reference to complete my PoC on Azure. Use the link to install and setup DBT. Using DBT we will transform the data and create gold layer. https://piethein.medium.com/using-dbt-for-building-a-medallion-lakehouse-architecture-azure-databricks-delta-dbt-31a31fc9bd0
Final state of databricks and DBT are available in my git repos. https://github.com/rameshagowda/azuredatabricks https://github.com/rameshagowda/dbt-azuredatabricks
References:
- https://piethein.medium.com/using-dbt-for-building-a-medallion-lakehouse-architecture-azure-databricks-delta-dbt-31a31fc9bd0
- https://www.youtube.com/watch?v=KsO2FHQdILs
- https://anujsen02.medium.com/analytics-engineering-on-the-lakehouse-using-dbt-databricks-part-1-c4d773731ffe
- https://app.pluralsight.com/library/courses/building-etl-pipeline-microsoft-azure-databricks/table-of-contents
- https://www.youtube.com/watch?v=x3-qUw9XWMA